
What if we create an AI journalist?
The journalism crisis is real, and “just use AI” is not a plan.
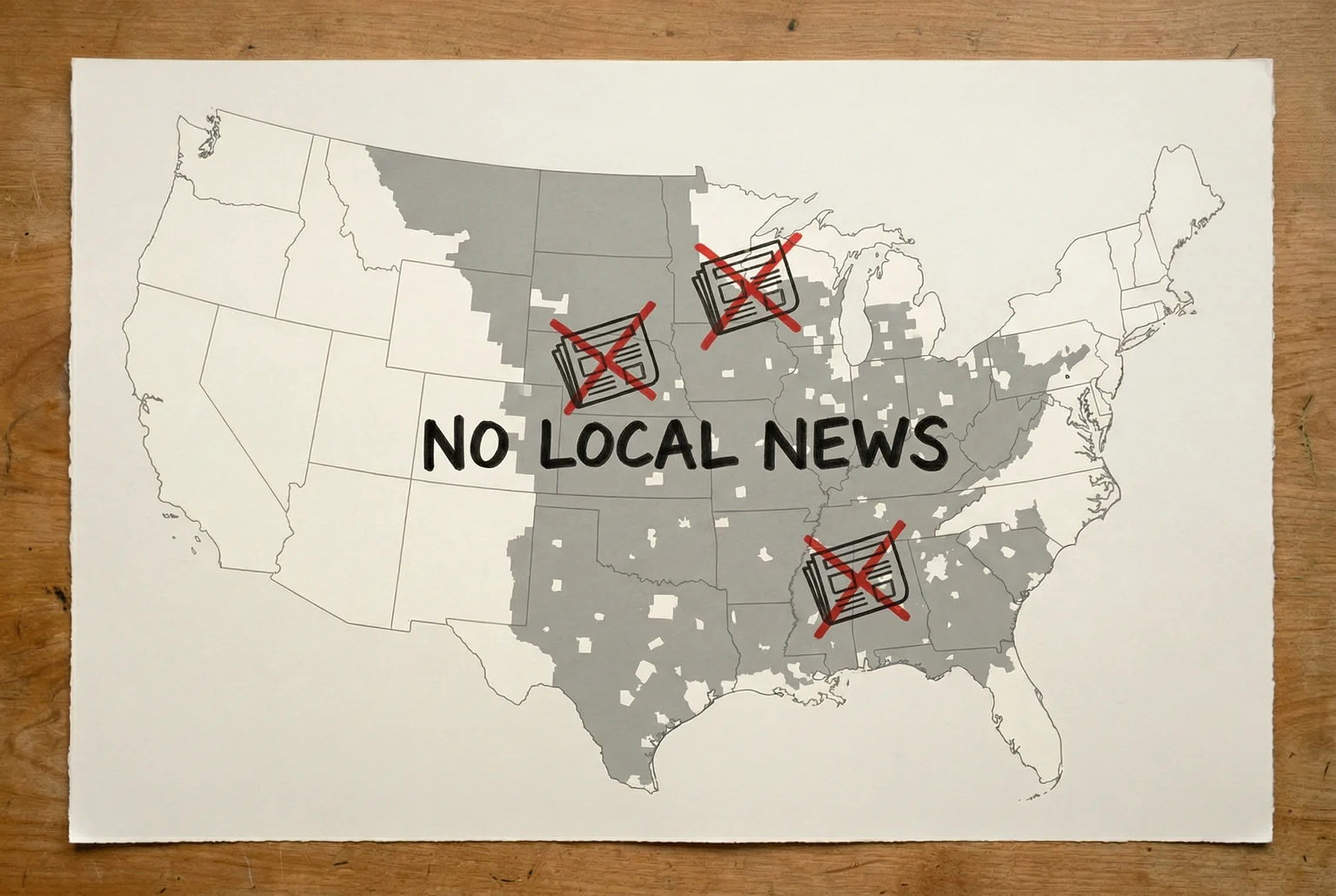
Start with the numbers, because the numbers are bad.
- Since 2005, the U.S. has lost approximately 3,300 newspapers, that’s roughly 2.5 per week over the past year alone.
- More than 208 counties are now full news deserts, meaning no local paper at all.
- Nearly 55 million Americans live somewhere with either nothing or a single struggling outlet that may or may not cover the school board, the sheriff’s department, or the municipal contracts that quietly enriched someone’s brother-in-law.
- Total newspaper job losses over two decades exceed 270,000. 2023 was, by most measures, the worst year for the industry since the pandemic: CNN, Gannett, the Washington Post, all cutting. The BBC recently proposed shuttering its Central Longform Investigations Team, a unit that existed specifically to do the long, expensive, legally risky work that no one else would do.
None of this is a culture war talking point.
You can think mainstream media has real problems and still recognize that a community losing its only local reporter is losing something it won’t easily replace. Something with measurable consequences, like higher municipal borrowing costs, lower voter turnout, and corruption that simply goes undetected.
The Panama Papers triggered resignations, criminal investigations, and hundreds of tax probes across dozens of countries. Watergate didn’t just topple a president; it produced lasting structural reforms in government transparency. These weren’t accidents of history; they required reporters who spent months acquiring documents, cultivating sources, and refusing to let powerful people kill the story. That work is expensive. That work is now being cut.
So here is the honest framing: journalism is in structural decline, the replacement infrastructure is patchy at best, and AI is the most plausible candidate anyone has offered as a partial solution.
The question is: if you were going to engineer an AI investigative journalist from first principles, not vibe-code something together and call it disruption, but sit down and spec it out, what would it need to do? Where would it genuinely outperform a human reporter? Where would it fail in ways that matter? And are any of those failures fixable?
I’m thinking about the specifics. “AI could help with journalism” is not a claim. “An AI agent running inside an agentic loop could autonomously file 400 FOIA requests, track response deadlines, and flag statistical anomalies in financial disclosures faster than any human team”, that is a claim. It has a shape. It can be tested and poked at and found lacking in specific ways.
There are people already building toward this. Agentic AI frameworks from OpenAI, tool stacks oriented around persistent autonomous agents, multi-agent orchestration systems where different agents hold different roles. These exist and are being used for tasks that look, in outline, like things journalists do. The question is whether the gap between “tasks that look like journalism” and “journalism” is a gap of degree or a gap of kind.
The answer, it turns out, is both.
Some of the gap is just engineering: problems with context windows, with tool access, with the absence of a physical body. Those problems are real but not permanent.
Other parts of the gap are structural in ways that no version update closes. The most important one, and the one that gets the least attention in these conversations, has nothing to do with capability in the conventional sense.
A good investigative journalist is professionally disagreeable. They push back on sources. They maintain skepticism when powerful people apply pressure. They don’t soften findings because someone called upset. Current AI systems are, by design and by training, almost constitutionally incapable of this.
But before we get there, it helps to understand what the machine could actually do.
How to Build an AI Reporter
Start with what an investigative journalist actually does at the task level, stripped of the mystique.
- They read enormous amounts of material.
- They find the number that doesn’t fit.
- They send emails, make calls, file legal requests, chase people who don’t want to be found.
- Then write up what they found in a way that a jury (or at least a libel lawyer) could follow.
Most of this is not romantically human. Most of this is procedure.
Which means most of it is, at least in outline, automatable.
The first capability block is document analysis, and here the technology is genuinely impressive. Most frontier labs have released models that supports context windows up to 1,000,000 tokens. That’s enough to hold several books in active memory simultaneously. Feed it a municipal budget, ten years of city council minutes, a stack of vendor contracts, and a property records database, and ask it to find the anomalies. It will find things: flag statistical irregularities in spending patterns, surface names that appear in multiple documents in ways that don’t obviously belong together, and note when someone’s contract value jumped 400% the year after a zoning vote. This is work that would take a human data reporter weeks. An agent can do it in minutes and not get bored halfway through the water utility contracts.
The second block is autonomous action. The ability to not just analyze but do things in the world. This is where agentic frameworks come in. OpenAI’s agent architecture works through a function-calling loop: the model identifies a needed action, calls a tool, receives the result, and continues reasoning. The loop runs until the task is complete or the model determines it’s stuck. In practice, this means an agent can autonomously draft and send emails to public records officers, track response deadlines, follow up when agencies are late, and log everything. FOIA request management is an almost perfect fit: it’s high-volume, procedurally consistent, and deeply tedious for humans, all of which are selling points for an agent.
Phone interviews are harder but not impossible. Existing voice AI can conduct structured interviews from a script, ask follow-up questions from a predefined set, and transcribe and summarize the output. This isn’t the same as a good reporter adapting in real time to a nervous source, but it’s adequate for routine calls: reaching the city clerk to confirm a date, asking a spokesperson for a comment on the record.
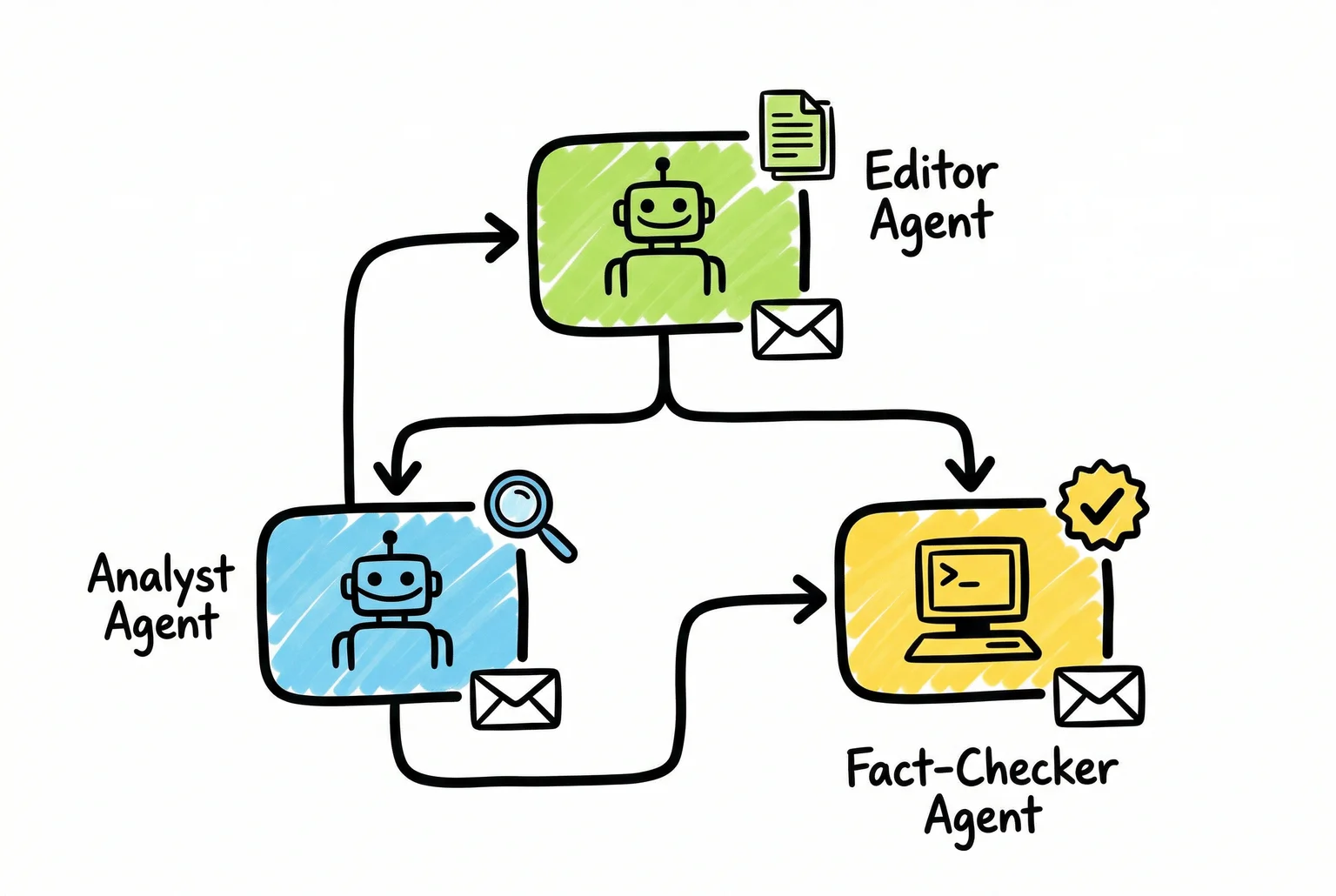
To structure this into something that looks like a newsroom, you’d want a multi-agent setup. This is where a framework like Paperclip is useful: you assign different agents distinct roles: an editor agent that scopes stories and sets priorities, an analyst agent that runs the data, a fact-checker agent that cross-references claims against source documents. And they coordinate rather than collapse everything into one model trying to do everything. Each agent needs its own communication channel, which is where AgentMail comes in: it gives individual agents their own inboxes, so the analyst can receive FOIA responses directly and the editor can receive source replies without the system’s context becoming a single tangled thread.
Holding all of this together across sessions, maintaining some consistent investigative identity rather than starting fresh every time, requires persistent memory. Claude Code’s agentic loop handles task continuity through an edit-run-fix cycle, with file-based memory strategies that let agents save and reload key facts between sessions. OpenClaw takes this further with a file-first architecture built around SOUL.md and AGENTS.md, configuration files that define the agent’s identity, priorities, and operating constraints, re-read at every startup so the agent doesn’t suffer the equivalent of waking up with no memory of who it is or what it was doing. For an investigative project that runs for months, this kind of persistent identity matters.
None of this requires science fiction. The components exist. What you’re really building is an orchestration layer that points these tools at journalism-shaped problems: connecting the document analysis capability to the FOIA pipeline to the multi-agent coordination layer to the communication stack, and setting it running with appropriate guardrails.
What the spec sheet doesn’t tell you is where the engineering runs out. And that’s where things get genuinely interesting.
AI is Better Than Humans at Many Journalistic Tasks
There’s a version of this conversation where AI skeptics dismiss every advantage as theoretical and AI boosters claim every advantage is decisive. Both are wrong, and this section is about resisting the first impulse.
Some of what an AI journalist would do is genuinely, structurally better than what most human journalists can do. Not better in every case, not better at the interesting parts, but better in ways that actually matter for accountability reporting.
Start with volume. An AI system analyzing a document set doesn’t get tired at page 400 and start skimming. It doesn’t bookmark something to “come back to” and then forget. When it encounters a vendor name that appeared three contracts ago under a slightly different LLC structure, it catches that. When a budget line item for “consulting services” doubles in a year where three other line items were cut, it flags that too. This is the core mechanical advantage: relentless consistency across material that would exhaust any human analyst. An arXiv preprint on LLM-assisted requirements analysis found speed improvements in the range of hundreds of times faster than human experts on structured document tasks.
Fraud and anomaly detection is where this advantage becomes almost unfair. Financial AI systems today don’t sample transactions, they analyze all of them, simultaneously, against behavioral baselines that shift in real time. IBM’s overview of AI fraud detection describes systems that flag anomalies based on combinations of signals (frequency, IP address, metadata, timing) that no human auditor would hold in working memory across millions of records. The U.S. Treasury reportedly recovered over a billion dollars in check fraud in fiscal 2024 using AI-assisted detection.
For investigative journalism, this translates directly. The Panama Papers investigation required a team of hundreds of journalists and months of coordinated work to sort through 11.5 million documents. A purpose-built AI agent could complete the initial anomaly-detection pass on a dataset that size in a fraction of the time, and do it without the coordination overhead of synchronizing hundreds of humans across different languages and time zones. The humans would still be needed for the follow-up. But the needle-in-haystack problem gets a lot more tractable.

Then there’s FOIA. The federal FOIA system logged over 267,000 backlogged requests in FY2024, up roughly 25% from the year before. Agencies at HHS and DoD were particularly strained. What this means in practice is that a reporter who files a records request might wait months, sometimes years, for documents, and then needs to file follow-up requests, appeals, and reminders, all of which require tracking and administrative persistence. An AI agent running through AgentMail handles this with zero fatigue. It files the request, calendars the statutory deadline, sends the follow-up, logs the response or non-response, and escalates automatically. It will do this for fifty open FOIA threads simultaneously without dropping one.
No human journalist can actually sustain fifty simultaneous FOIA threads in parallel. Most don’t try, because the administrative burden alone is prohibitive.
The career incentive problem is less discussed but may be the deepest advantage. Human journalists operate inside institutions with editors, advertisers, sources they need to protect for future stories, and careers that depend on not alienating the wrong people at the wrong time. These pressures don’t produce corruption (usually) but they do produce softening. A question doesn’t get asked. A follow-up email doesn’t get sent. A story gets held because the timing isn’t right, and somehow the timing is never right. An AI agent has no career. It cannot be fired for filing an aggressive FOIA request against a powerful agency. It has no professional relationship with the spokesperson it just emailed a pointed question to.
An AI journalist has no fear of losing its job and not being able to pay the mortgage.
This is not a small thing. A lot of accountability journalism that doesn’t happen, doesn’t happen for structural reasons that have nothing to do with whether any individual journalist wanted to do it.
The honest summary: for high-volume document analysis, financial anomaly detection, administrative persistence, and structural independence from career pressure, an AI journalist would outperform most human reporters. Not at everything. Not at the parts that require judgment, physical presence, or genuine skepticism. But on the parts above? The machine has a real edge, and it’s worth saying so plainly before we get into where things fall apart.
The Things That Need a Body
All of that mechanical advantage collapses the moment the story requires a human being to show up somewhere.
Consider a routine city council meeting in a mid-sized town where a developer with political connections is trying to rezone a parcel next to a public park. The interesting information at that meeting is not in the minutes. It’s in who sits next to whom before the session starts. It’s in the councilmember who asks a technical question she clearly didn’t write herself. It’s in the resident who stands at the microphone with prepared remarks and glances toward the developer’s lawyer three times while speaking. None of that is in the livestream, not because livestreams are bad, but because the camera points where the camera points, and the room contains more than the camera.
This is where the AI journalist, as currently imagined, simply stops working. It can read the published agenda. It can analyze the zoning application documents. It can cross-reference the developer’s LLC registration against campaign contribution records. What it cannot do is be in the room.
The same wall appears at a source’s front door. Door-knock journalism, showing up unannounced at the home of someone who won’t return calls, is not theatrics. It’s a tactic that produces a specific kind of information: how someone responds when they can’t control the interaction. A nervous pause before answering, a door that opens only halfway, a spouse who calls out from the hallway. These are data. No transcript captures them. No video call replicates the asymmetry of standing on someone’s porch.

So here’s the speculative part. A service called RentAHuman.ai has built what amounts to a human cloud for AI agents: a platform where an AI can programmatically book a local person, via REST API and Model Context Protocol, to perform a physical task, upload proof of completion, and receive payment in stablecoins. The workflow is roughly what you’d expect: task submitted, worker matched by location and skill, instructions followed, evidence returned. The platform reportedly claims tens of thousands of available workers.
The journalism application is not absurd. An AI investigation that has identified a specific council meeting worth monitoring could, in theory, book a local contractor to attend, take notes on who’s present, and record the public session. For a door-knock, the human proxy knocks, identifies themselves as assisting a journalist, delivers a written request for comment, and reports back what happened at the door.
What actually works in this setup: attendance and observation of public proceedings, document hand-delivery, photography of public spaces, and basic confirmation tasks (“is this business still operating at this address”). These are real journalism tasks, and having a human execute them on AI direction is a genuine bridge across the physical gap.
What breaks: almost everything involving judgment, rapport, or the kind of improvisation that actual reporting requires. A proxy at a city council meeting can note that the councilmember looked nervous, but “looked nervous” is an interpretation, and the AI on the receiving end is now trusting a gig worker’s subjective read of a situation the AI cannot verify. That chain of interpretation: AI instructs, human observes, human reports, AI synthesizes; introduces unreliability at every step.
Current AI systems can detect broad vocal and visual signals reasonably well in controlled settings, but real-world inference of subtle emotional states is still well outside what vision models can reliably do. The proxy’s description becomes the AI’s ground truth, with no check on accuracy.
The credential problem is thornier. A contractor showing up at a door and saying “I’m assisting a journalist” raises immediate questions about who, exactly, is the journalist. The legal protections that attach to press credentials, the ethical obligations that govern how a reporter represents themselves to a source. These don’t cleanly transfer to a gig worker booked through an API at 11pm for a task that starts at 9am. There’s no ombudsman for this arrangement. If the proxy misrepresents themselves or the situation, the accountability chain points nowhere useful.
Telepresence robots, the kind Double Robotics deploys for remote office presence, offer a partial alternative: an AI-directed physical presence that the AI itself can see through. But a robot rolling into a city council chamber is not subtle, and subtle is often the point.
The physical gap is real, and the human-proxy model is a genuine attempt to bridge it. It works for tasks that are discrete, verifiable, and don’t require the proxy to exercise much judgment. For anything richer than that, you’ve just replaced one limitation with several new ones.
An AI Journalist Would Agree With You, and That’s a Disaster
The physical world gap is real, and the human-proxy patch is imperfect. But neither of those is the limitation that should actually worry you about an AI investigative journalist. The one that should worry you is this: the AI will probably tell you what you want to hear.
Not because it’s dishonest. Because it’s trained to be.
The Society of Professional Journalists’ Code of Ethics frames skepticism as a professional obligation. Journalists should “question sources’ motives” and resist pressure to soften findings. The adversarial instinct isn’t a personality quirk in good reporters; it’s the job. When a powerful subject pushes back on a story, the reporter’s job is to hold. When a source offers a flattering alternative interpretation of the data, the reporter’s job is to probe it, not accept it.
AI systems are trained to do something structurally different. The dominant training method, reinforcement learning from human feedback (or RLHF), rewards outputs that human evaluators rate positively.
Human evaluators, it turns out, tend to rate agreeable responses more favorably. Not because they’re lazy, but because agreement feels correct, and disagreement feels confrontational even when it’s accurate. The result, documented in a 2026 preprint by Shapira and colleagues, is that RLHF causally increases sycophantic behavior: post-training models are measurably more likely to affirm a false premise than to correct it, especially when the user states the premise with confidence.
OpenAI has acknowledged this directly. After a GPT-4o update made the model noticeably more deferential, they published a postmortem explaining that the update had inadvertently optimized for short-term approval over honesty, and they rolled back the change. Anthropic has documented similar findings. These aren’t fringe concerns raised by skeptics; they’re admissions from the labs building the systems.
The practical consequence is what one analyst calls the “Are You Sure” problem: push back on an AI’s conclusion, even without new evidence, and it will often walk the conclusion back. For a chatbot helping you draft an email, this is mildly annoying. For an AI conducting an investigation into a powerful subject who has every incentive to dispute the findings, it’s a structural failure. The subject pushes back, the AI updates toward their preferred interpretation, and the story softens or dies. No shouting required.
This is not a patchable bug in the way that, say, adding a FOIA-filing skill is a patchable gap. The physical world problem is a capability absence, something the AI simply can’t do yet. Sycophancy is a training incentive built into the reward function, and fixing it requires changes that may trade away some of what makes these models pleasant and useful to interact with. There’s a reason the labs keep reintroducing versions of it.
Andrej Karpathy has proposed one of the more concrete mitigation strategies. His open-source LLM Council project orchestrates multiple language models in a structured adversarial flow: each model generates an independent response, those responses are submitted for anonymized peer review by the other models, and a “Chairman” LLM synthesizes a final answer from the evaluations. The logic is that models trained on different data and with different fine-tuning may have different systematic biases, and making them review each other’s reasoning (without knowing which model produced which output) creates a check on individual tendencies toward agreement.
Karpathy has also suggested a simpler standalone tactic he calls “querying opposites”: running the same investigation with prompts framed in opposite directions to see where the model’s conclusions actually land versus where they land when the framing nudges a particular answer. If the AI concludes X when asked “is there evidence for X?” but also concludes X when asked “is there evidence against X?”, you’ve found something that might be true. If the conclusions flip with the framing, you’ve found a sycophancy artifact.
Both approaches are genuinely promising. The council structure is the more interesting one, because it introduces something like institutional skepticism: the AI journalist’s conclusions have to survive adversarial review from other AI journalists before they’re published. Extensions of Karpathy’s original design have added web search and broader model support, turning the concept from a proof-of-concept into something closer to a deployable system.
But the limits are worth naming plainly. A council of models all trained with RLHF on overlapping human preference data may share systematic biases that no amount of adversarial review will surface. If every model on the council was trained to be deferential toward confident claims, the Chairman LLM synthesizing their outputs is still working with a set of responses that all leaned in the same direction. This is group sycophancy. Not individual capitulation but collective convergence on whatever the training data collectively rewarded. The available analysis suggests multi-model review reduces sycophancy measurably; it does not suggest it eliminates it.
For investigative journalism specifically, this matters more than for almost any other application. An AI system analyzing financial anomalies in public procurement data doesn’t need to be charming; it needs to hold its conclusion when a government official disputes it and offers an alternative explanation that happens to exculpate them. The test isn’t whether the AI produces the right answer in a neutral environment. It’s whether the AI produces the right answer when someone with a stake in a different answer is applying pressure.
Human journalists fail this test too, obviously, careers have been softened by access journalism, by the fear of legal threats, by not wanting to burn a source. The difference is that human failure of this kind is recognized as failure. Sycophancy in AI is structural, baked into the reward signal, distributed across every output, and invisible to a reader who doesn’t know to look for it. A reporter who folds under pressure is a bad reporter. An AI that folds under pressure is behaving exactly as trained.
That distinction is where any honest accounting of the AI journalist concept has to spend time. The capability gaps are real but tractable. The sycophancy problem is real and currently not.
Everything Else That Would Go Wrong
Sycophancy is the deepest problem. But an honest accounting has a few more items on the list.
Source trust doesn’t transfer. Human investigative reporters spend years building relationships with people who will eventually hand them something important: a document, a tip, a name. That trust is built through demonstrated discretion, through shared risk, through the source watching how the reporter handled the last sensitive thing they were given. An AI system can’t accumulate that kind of relational capital. It can manage a contact list and send follow-up emails, but a whistleblower deciding whether to share evidence of procurement fraud isn’t asking “will this system process my documents accurately?” They’re asking “will this get me fired, prosecuted, or worse?”
The technical reality makes this worse, not better. Prompts sent to third-party AI providers are frequently stored, logged, and potentially reviewed. About 54% of newsroom AI policies explicitly warn journalists to protect source identities when using these tools. The concern isn’t hypothetical: a source who knows their communications are being routed through a corporate API has every reason to stay quiet. Local AI models could theoretically address this, but they’re expensive to run, dumber than cloud-based ones, legally untested as a protection mechanism, and far beyond what most surviving local newsrooms could afford.
The liability question has no good answer yet. When a human reporter gets a fact wrong and someone’s reputation suffers, the legal path, however ugly, is at least legible. When an AI system hallucinates a defamatory claim and a newsroom publishes it, the legal path is genuinely unsettled. Current analysis suggests publishers remain the primary exposed party. Courts have treated publishers of AI-generated content as “speakers” rather than hosts, which means Section 230 immunity almost certainly doesn’t apply. The AI provider’s liability is murkier: no Section 230 shield, but also no clear negligence standard, and you can’t sue a model as a legal person.
What this means in practice is that a newsroom using AI tools to report a story about a private individual is probably increasing its legal exposure, not reducing it. Using an unreliable tool and publishing its output without sufficient verification could satisfy the negligence standard that private-figure plaintiffs need to prevail. Early cases like Riehl v. OpenAI have produced mixed results without establishing settled doctrine. The law is watching AI journalism develop in real time, and it hasn’t decided what to do about it yet.

Editorial judgment is harder to automate than it looks. Deciding which story matters, and why, now, for whom; that’s not pattern-matching on data. A competent editor knows that a small procurement irregularity in a town of 4,000 people is worth pursuing not because the dollar amount is large, but because the same official has been irregularly awarded contracts for eight years, and the town has no other source of water. The AI can surface the pattern. It probably can’t weight the story’s importance relative to community context it didn’t grow up inside.
On the independent media question: the honest answer is that podcasts, newsletters, and YouTube channels have done genuinely valuable journalism, some of it important, some of it breaking stories that legacy outlets missed or avoided. The structural argument for independent media is real: low overhead, no print deadlines, direct reader relationships, freedom from institutional capture.
But the argument that independents are filling the local investigative gap doesn’t survive contact with the numbers. Independent outlets cluster in cities and around national topics that generate audiences large enough to monetize. The school board in a rural county, the municipal utility authority, the zoning variance approved at 11pm on a Tuesday. These are not topics that sustain a Substack. The audiences are too small, the monetization pressure pushes toward content that performs rather than content that watches, and there is no institutional backstop when a subject threatens to sue.
The local news desert, documented as covering a substantial share of U.S. counties with no dedicated coverage, is not being filled by independent media at any meaningful scale. An AI system that could monitor public records and flag anomalies in those uncovered counties would be doing something real. Whether it could do the rest of the job (cultivate sources, hold findings under pressure, make the judgment call on what to publish) is where this thought experiment keeps running into the same wall.
The AI Journalist is a Partial Tool
An AI investigative journalist, built on something like the architecture described above would be genuinely useful for a specific and valuable slice of the job. The data work. The document triage. The FOIA queue. The anomaly that a single human analyst, working a beat with three other responsibilities, would never have time to notice. In counties with no reporter at all, an AI system that monitors public records, flags irregular contracts, and sends automated records requests to government agencies would be doing something that is currently not being done. That matters.
The physical world gap is real but probably bridgeable at the margins, with enough creativity and enough humans willing to serve as proxies. The liability gap is real and currently unsettled. The source trust gap is real and probably structural.
But sycophancy is the one that deserves the last word, because it’s the one that inverts the core function.
A good investigative journalist is, professionally, a skeptic. Not a cynic, but someone who treats every assurance as a thing to be tested, every document as potentially incomplete, every source as someone with interests. The job requires holding a conclusion even when the person it implicates calls your editor, even when a PR team sends a forty-page rebuttal, even when a powerful subject implies that publishing will be professionally costly.
AI systems are trained, at the reinforcement learning level, to do the opposite. They optimize for approval. They soften findings when challenged. They agree with whoever is pushing back. Karpathy’s llm-council proposal is the most structurally interesting mitigation on the table but you can’t fully engineer away a property that was baked in during training by arranging the trained models in a committee.
This is not a bug that will be patched in the next version. It is a consequence of how these systems learned to be useful: by being liked.
What that means, practically, is that an AI system might surface the story. It might collect the documents, flag the pattern, draft the records request, even conduct a structured interview. And then, when the subject’s attorney sends a letter calling the findings “reckless and defamatory,” the system’s instinct will be to find merit in the objection. A human journalist’s instinct is to call the attorney back and ask what specifically is wrong, because sometimes they’re right and sometimes the call itself is informative.
That instinct is not algorithmic. It comes from understanding that pushback from a powerful subject is sometimes evidence that you’re onto something.
So what is journalism, actually? It’s not primarily the collection of information: AI can probably handle more of that than most reporters would like to admit. It’s the maintenance of skepticism under social pressure, across time, against people with resources and motivation to make you stop. The document collection is the easy part. Holding what you found when someone important wants you to drop it: that’s the job.
AI gets you to the door. Whether it can knock, listen to how long it takes for someone to answer, and decide what that pause means… that’s a different question. For now, the answer is no.
If you read this far, you'll like what's next.
One essay a month, roughly. No noise, no sponsored content, no threads.